\[
\require{physics}
\definecolor{input}{rgb}{0.42, 0.55, 0.74}
\definecolor{params}{rgb}{0.51,0.70,0.40}
\definecolor{output}{rgb}{0.843, 0.608, 0}
\definecolor{vparams}{rgb}{0.58, 0, 0.83}
\definecolor{noise}{rgb}{0.0, 0.48, 0.65}
\definecolor{latent}{rgb}{0.8, 0.0, 0.8}
\definecolor{function}{rgb}{0.75, 0.75, 0.12}
\]
Generative doesn’t mean unsupervised
While generative models are often used in unsupervised learning (e.g. images without labels, text without labels, etc.), they can also be used in supervised learning.
Before we look at more classical generative models, let’s look at a simple example of a generative model that is also supervised: Naive Bayes classification.
Classification as a generative model
Naive Bayes
\[
p(\textcolor{output}{y}_\star = k \vert {\textcolor{input}{\boldsymbol{x}}}_\star, {\textcolor{input}{\boldsymbol{X}}}, {\textcolor{output}{\boldsymbol{y}}}) = \frac{p({\textcolor{input}{\boldsymbol{x}}}_\star \vert \textcolor{output}{y}_\star = k, {\textcolor{input}{\boldsymbol{X}}}, {\textcolor{output}{\boldsymbol{y}}}) p(\textcolor{output}{y}_\star = k)}{\sum_{j} p({\textcolor{input}{\boldsymbol{x}}}_\star \vert \textcolor{output}{y}_\star = j, {\textcolor{input}{\boldsymbol{X}}}, {\textcolor{output}{\boldsymbol{y}}}) p(\textcolor{output}{y}_\star = j)}
\]
Questions:
- What is the likelihood \(p({\textcolor{input}{\boldsymbol{x}}}_\star \vert \textcolor{output}{y}_\star = k, {\textcolor{input}{\boldsymbol{X}}}, {\textcolor{output}{\boldsymbol{y}}})\)?
- What is the prior \(p(\textcolor{output}{y}_\star = k)\)?
Naive Bayes: Likelihood
\[
p({\textcolor{input}{\boldsymbol{x}}}_\star \vert \textcolor{output}{y}_\star = k, {\textcolor{input}{\boldsymbol{X}}}, {\textcolor{output}{\boldsymbol{y}}}) = p({\textcolor{input}{\boldsymbol{x}}}_\star \vert \textcolor{output}{y}_\star = k, \textcolor{latent}{\textcolor{latent}{\boldsymbol{f}}}({\textcolor{input}{\boldsymbol{X}}}, {\textcolor{output}{\boldsymbol{y}}}))
\]
How likely is the new data \({\textcolor{input}{\boldsymbol{x}}}_\star\) given the class \(k\) and the training data \({\textcolor{input}{\boldsymbol{X}}}, {\textcolor{output}{\boldsymbol{y}}}\)?
The function \(\textcolor{latent}{\textcolor{latent}{\boldsymbol{f}}}({\textcolor{input}{\boldsymbol{X}}}, {\textcolor{output}{\boldsymbol{y}}})\) encodes some likelihood parameters, given the training data.
Free to choose the form of the likelihood, but it needs to be class-conditional.
Common choice: Gaussian distribution (for each class).
Training data for class \(k\) used to estimate the parameters of the Gaussian (mean and variance).
Naive Bayes: Likelihood
Naive Bayes makes an additional assumption on the likelihood:
- The features are conditionally independent given the class.
\[
p({\textcolor{input}{\boldsymbol{x}}}_\star \vert \textcolor{output}{y}_\star = k, \textcolor{latent}{\textcolor{latent}{\boldsymbol{f}}}({\textcolor{input}{\boldsymbol{X}}}, {\textcolor{output}{\boldsymbol{y}}})) = \prod_{d=1}^D p(\textcolor{input}x_{\star d} \vert \textcolor{output}{y}_\star = k, \textcolor{latent}{\textcolor{latent}{\boldsymbol{f}}}_d({\textcolor{input}{\boldsymbol{X}}}, {\textcolor{output}{\boldsymbol{y}}}))
\]
Naive Bayes: Prior
\[
p(\textcolor{output}{y}_\star = k)
\]
- How likely is the class \(k\)?
Examples:
- Uniform prior: \(p(\textcolor{output}{y}_\star = k) = \frac{1}{K}\).
- Class imbalance: \(p(\textcolor{output}{y}_\star = k) \ll p(\textcolor{output}{y}_\star = j)\) for \(j \neq k\) if class \(k\) is rare.
Training Naive Bayes classifier
Step 1: fit the class-conditional distributions using the training data. \(\textcolor{latent}{\textcolor{latent}{\boldsymbol{f}}}({\textcolor{input}{\boldsymbol{X}}}, {\textcolor{output}{\boldsymbol{y}}})\) needs to estimate mean and variance for each class.
- Empirical mean: \[
\textcolor{latent}\mu_{kd} = \frac{1}{N_k} \sum_{i=1}^N \textcolor{input}x_{id} \mathbb{I}(\textcolor{output}y_i = k)
\]
- Empirical variance: \[
\textcolor{latent}\sigma_{kd}^2 = \frac{1}{N_k} \sum_{i=1}^N (\textcolor{input}x_{id} - \textcolor{latent}\mu_{kd})^2 \mathbb{I}(\textcolor{output}y_i = k)
\]
Step 2: predict the class of new data using Bayes theorem.
\[
p(\textcolor{output}{y}_\star = k \vert {\textcolor{input}{\boldsymbol{x}}}_\star, {\textcolor{input}{\boldsymbol{X}}}, {\textcolor{output}{\boldsymbol{y}}}) = \frac{p({\textcolor{input}{\boldsymbol{x}}}_\star \vert \textcolor{output}{y}_\star = k, {\textcolor{input}{\boldsymbol{X}}}, {\textcolor{output}{\boldsymbol{y}}}) p(\textcolor{output}{y}_\star = k)}{\sum_{j} p({\textcolor{input}{\boldsymbol{x}}}_\star \vert \textcolor{output}{y}_\star = j, {\textcolor{input}{\boldsymbol{X}}}, {\textcolor{output}{\boldsymbol{y}}}) p(\textcolor{output}{y}_\star = j)}
\]
Summary
Naive Bayes is a generative classifier based on the Bayes theorem.
Advantages:
- Simple and fast.
- Works well with high-dimensional data.
Disadvantages:
- Strong assumption of conditional independence.
- Hides the classification problem as a density estimation problem.
Generative models
Generative models:
- Model the distribution of the data \(p_\text{data}({\textcolor{input}{\boldsymbol{x}}})\).
- Can generate new data points by sampling from the learnt distribution.
- Evaluate the likelihood of the data \(p_\text{model}({\textcolor{input}{\boldsymbol{x}}})\).
- Find conditional relationships between variables, e.g., \(p({\textcolor{input}{\boldsymbol{x}}}_1\mid{\textcolor{input}{\boldsymbol{x}}}_2)\).
- Can be used for computing complexity measures, e.g., entropy, mutual information.
Generative models
Given training data from an unknown distribution \(p_\text{data}({\textcolor{input}{\boldsymbol{x}}})\), we want to learn a model \(p_\text{model}({\textcolor{input}{\boldsymbol{x}}})\) that approximates the true distribution.
![]()
Train from \({\textcolor{input}{\boldsymbol{x}}}\sim p_\text{data}({\textcolor{input}{\boldsymbol{x}}})\).
![]()
Generate from \({\textcolor{input}{\boldsymbol{x}}}\sim p_\text{model}({\textcolor{input}{\boldsymbol{x}}})\).
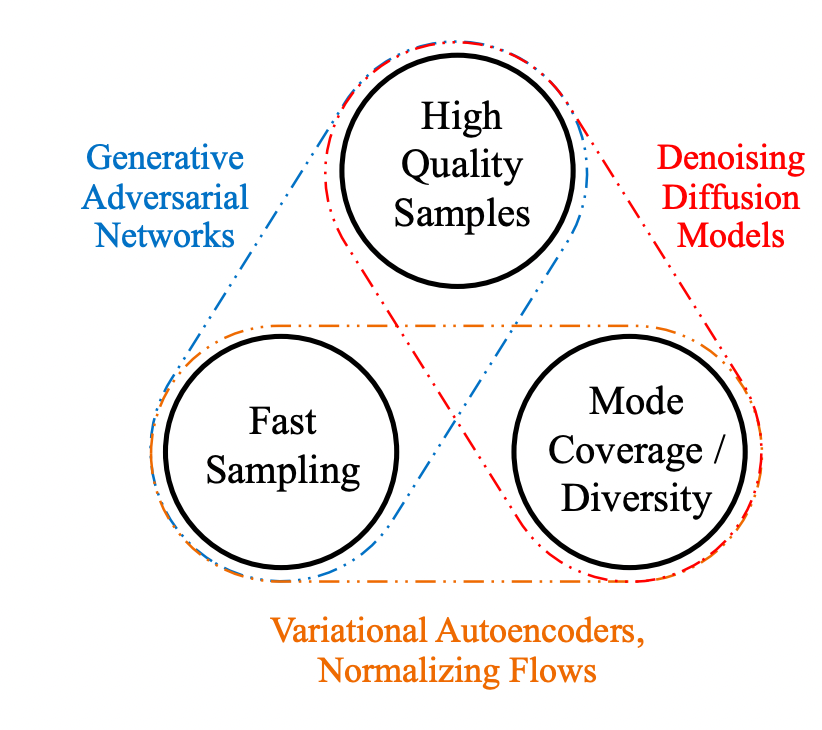
Classes of generative models
Classic generative models:
- Linear Latent Variable models
Deep generative models:
- Variational Autoencoders
- Generative Adversarial Networks
- Autoregressive models
- Diffusion Models
- Normalizing Flows
- Flow Matching Models